


Edge Computing - wyzwania na brzegu procesu
W automatyce przemysłowej funkcjonuje kilka tzw. buzz words, które są często stosowanie w kontekście przewidywań nt przyszłości branży. Jednym z takich terminów jest z pewnością Edge Computing. Nie mamy jednej oficjalnej definicji oraz zakresu sprzętowego który należy do tej kategorii. Wszystko zależy od implementacji tego rozwiązania. Często spotykaną definicją edge computingu jest "kratowa sieć mikrocentrów danych". Jest to w pełni poprawne określenie pod względem technologicznym, jednak nie mówi nam dużo o samej naturze tych systemów i potrzebach które uzasadniają ich wykorzystanie. W tym materiale omówimy dokładnie to, czym jest Edge Computing oraz jaki może mieć wpływ na nasze aplikacje.
Czym jest Edge Computing?
Żeby odpowiedzieć na to pytanie, musimy zadać inne: Co jest obecnie najważniejszą "walutą" w automatyce przemysłowej? Są to oczywiście szeroko pojęte dane. Generowanie i zbieranie ich przez urządzenia stanowi nie tylko podstawę istnienia procesu, ale również daje możliwość jego optymalizacji, a w konsekwencji zwiększenia rentowności.
Jednak aby osiągnąć ten cel, musimy przetworzyć zebrane dane i wynieść z nich realną wartość dla naszego procesu bądź systemu. To z kolei generuje kolejne, co najmniej dwie potrzeby: ciągłego przesyłania ich w czasie rzeczywistym oraz zapewnienia funkcjonowania systemu centralnej analizy danych.
Nie w każdym przypadku zapewnienie tych potrzeb jest możliwe. Niektóre aplikacje IoT pracują w środowisku, w którym zapewnienie wystarczająco szybkiej transmisji danych nie jest fizycznie możliwe, bądź koszty z tym związane nie posiadają uzasadnienia ekonomicznego. Przykładem takich aplikacji jest transport. Nowoczesne zespoły trakcyjne są wyposażone w systemy, których elementy możemy określić jako urządzenia internetu rzeczy. W takich warunkach system musi posiadać pewną dozę samodzielności w analizie zbieranych danych, ponieważ nie jesteśmy w stanie zagwarantować stabilnej łączności na całej trasie przejazdu. Szczególne znaczenie ma to w przypadku systemów bezpieczeństwa.
Często też zdarza się, że specyfika danego procesu lub charakter przedsiębiorstwa nie pozwalają na alokacje zbieranych danych u zewnętrznych partnerów (np. w silnie regulowanych branżach), a firmowe centra danych nie są w stanie wystarczająco szybko dokonywać obliczeń, ponieważ nastawione są głównie na ich przechowywanie.
Rozwiązaniem ideowym takich problemów jest przeniesienie analizy danych bliżej miejsca powstawania. Innymi słowy, przeniesienie obliczeń na krawędź procesu, czyli w dosłownym tłumaczeniu - edge computing.
Jest to podejście umożliwiające lokalne przetwarzanie danych, a następnie przesyłanie tylko kluczowych informacji do systemu nadrzędnego (np. SCADA, cloud). Znacznie ułatwia to utrzymanie ciągłej wymiany danych. Mniejsza ilość przesyłanych pakietów powoduje, że sieci nie wymagają wysokiej przepustowości.
Architektura Edge Computing
Jak powinna wyglądać? Zależy to głównie od typu danych oraz poziomu złożoności analizy dokonywanej lokalnie. Kolejnym ważnym czynnikiem jest również skala aplikacji - przy dużej ilości punktów generujących informacje, może wystąpić potrzeba spięcia ich w mniejsze podsystemy.
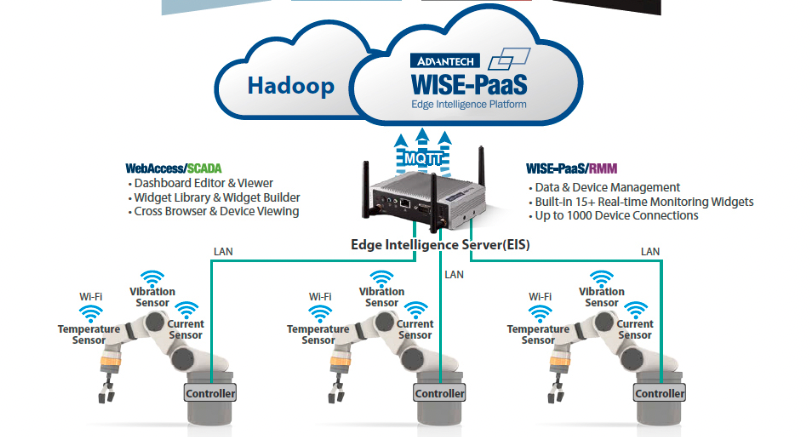
Zakładając przypadek minimalnego rozbudowania systemu, urządzeniem z zakresu Edge Computing może być pojedynczy czujnik temperatury/wilgotności, który samodzielnie monitoruje jakiś obiekt, a przesyła dalej jedynie alerty o przekroczeniu przewidzianych wartości krytycznych. W momencie, gdy takich urządzeń będzie np. 100, warto rozważyć ich podział (np. ze względu na lokalizacje w zakładzie) i zgrupowanie w kilka węzłów, za pomocą bardziej zaawansowanych urządzeń (np. sterownik PLC, Gateway). W takiej architekturze komunikację z centralnym systemem mają tylko urządzenia pośrednie (węzłowe).
Przy bardzie zaawansowanych systemach warto wybrać urządzenia brzegowe o wystarczającej mocy obliczeniowej, tak by stanowiły swojego rodzaju mikrocentra danych działające jako samodzielne punkty przetwarzania i niezbędnej archiwizacji danych. Do takich zadań potrzebujemy już komputera przemysłowego z systemem Windows lub Linux.
Edge Computing - rozwój technologii czy uwzględnienie jej ograniczeń?
Szacuje się, że obecnie około 20 mld urządzeń jest podłączonych do sieci, a wg przewidywań do 2025 roku liczba ta wzrośnie do 70 mld. Tak intensywny rozwój jest spowodowany w dużej mierze przez zwiększenie popularności internetu rzeczy. O ile w przypadku liczby urządzeń stricte IT mamy pewne ograniczenia, np. populacja ludzi na świecie, tak ilość urządzeń które mogą być wykorzystywane w aplikacjach IoT jest praktycznie nieograniczona.
Drastyczny wzrost strumieniowego przesyłania danych wymusił stworzenie nowego standardu sieci 5G. Szczególne znaczenie mają tutaj obszary przemysłowe (specjalne strefy ekonomiczne) oraz silnie zurbanizowane, ponieważ zagęszczenie urządzeń przesyłających dane do sieci jest zbyt duże do obsłużenia przez sieć 3/4G. Nie należy jednak zapominać o prostszych systemach komunikacji typu LPWLAN oraz LoRa, które również znajdują swoje miejsce w świecie systemów IoT. Dotyczy to zwłaszcza prostszych aplikacji wykorzystywanych w miejscach nie związanych bezpośrednio z automatyką przemysłową.
Ponadto, wzrost zainteresowania tematyką Industry 4.0 wymusza na producentach sprzętu przemysłowego tworzenie coraz wydajniejszych, kompaktowych rozwiązań Edge Computing. Takie urządzenia, ze względu na często trudne środowisko pracy muszą być wytrzymałe na wilgoć, wstrząsy i temperaturę. Ponadto, czynniki takie jak zapylenie uniemożliwiają zastosowanie wentylatorów. Stworzenie urządzenia łączącego wszystkie te cechy stanowi duże wyzwanie dla projektantów.
Kolejnym ważnym aspektem są protokoły komunikacyjne. W systemach Edge Computing klasyczna komunikacja przemysłowa (MODBUS, Profinet) nie zda egzaminu, ponieważ nie oferuje wystarczającej szybkości i lekkości transmisji (musimy pamiętać, że urządzenia IoT często posiadają stosunkowo ograniczone zasoby). Obecnie często spotyka się implementacje protokołów MQTT oraz Kaffka (szczególnie w systemach finansowych).
Pod tym względem możemy traktować Edge Computing jako czynnik napędzający rozwój technologii, jednak samo powstanie koncepcji wywodzi się z ograniczeń technologicznych oraz fizycznych. W przypadku mocno scentralizowanych systemów chmurowych (np. lokalizacja centrów danych AWS), musimy uwzględnić, że sygnał, czyli fala elektromagnetyczna, posiada skończoną prędkość.
Edge Computing, Cloud Computing, czy może Fog Computing?
W branży automatyki przemysłowej, z punktu widzenia dalszej analizy, mamy obecnie dwie główne architektury: omawiany edge computing oraz cloud computing. Klasyczny Cloud Computing napotyka przeszkody wymienione we wcześniejszych akapitach, a technologie brzegowe stanowią ich rozwiązanie. Jednak Edge Computing nie jest w żaden sposób konkurencją dla Cloud Computing, a wręcz przeciwnie.
Jeżeli połączymy te dwa podejścia i wyciągając z każdego kluczowe zalety, możemy stworzyć system zarówno odporny na wszelkie zakłócenia środowiskowe, jak i skalowalny, oparty na centralnej bazie danych działającej z dużą wydajnością obliczeniową. Takie podejście nazywamy fog computing - połączenie nadrzędnego systemu scentralizowanego, działającego w oparciu o dane dostarczane przez rozproszone systemy podrzędne.
Co do samej złożoności obliczeń przeprowadzanych na brzegu sieci, jest to zależne od konkretnej aplikacji i jej potrzeb. Ta właściwość ukazuje koleją ważną cechę tego rodzaju architektury - dużą dowolność wyborów wzorców projektowych.
Przykłady urządzeń Edge Computing
Skoro omówiliśmy już przykłady możliwych zastosowań Edge Computingu, omówmy teraz jakie urządzenia przemysłowe wpisują się w ten nurt. Aby zaprezentować przekrój wiodących rozwiązań, zaczniemy od podstawowych komponentów, a skończymy na najbardziej rozbudowanych.
- Rozproszone systemy I/O - podstawowe urządzenia internetu rzeczy, pozwalają na tworzenie ekonomicznych systemów pomiarowych. Architektura takich systemów w większości polega na rozwiązaniach typu node-accesspoint. Idea tego rozwiązania polega na umieszczeniu urządzeń brzegowych wykonujących swoją pracę lokalnie na tzn. "factory floor", a następnie podłączeniu ich do jednego Access Pointa. Często spotykanym rozwiązaniem do komunikacji tych urządzeń jest LPWALN (Low Power Wide Area Local Network), która umożliwia tworzenie sieci o niskiej przepustowości, ale dużym zasięgu. Wykorzystanie tego rodzaju komunikacji pozwala na wyposażenie urządzeń brzegowych jedynie w zasilanie bateryjne (podtrzymanie komunikacji i przesyłanie danych zużywa najwięcej energii), co niweluje problem z dostępem do infrastruktury energetycznej i sieciowej. Dopiero Access Point jest podłączony do systemu centralnej analizy danych i zasilany napięciem stałym (np. 24VDC).

- Gateway przemysłowy - nowoczesne gatewaye nie służą już tylko do konwersji protokołów, ale również spełniają funkcje hubów dla urządzeń IoT. Obecnie o jakości takiego urządzenia nie świadczy zdolność do zamiany protokołu Modbus RTU na Modbus TCP/IP, ale przede wszystkim:
- moc obliczeniowa,
- zaimplementowany system operacyjny,
- zdolność obsługi wielu technologii łączności,
- posiadanie certyfikatu zgodności z najpopularniejszymi platformami chmurowymi (AWS, Azure).
Coraz więcej urządzeń tej kategorii posiada zainstalowany system Linux, który sprawia, że możliwości wykorzystania narzędzi IT w celu integracji centralnej bazy danych działającej w istniejącej infrastrukturze jest bardzo proste. W przypadku środowisk o dobrze rozwiniętej infrastrukturze sieciowej i energetycznej takie rozwiązanie sprawdzi się bardzo dobrze, nawet w bardziej wymagających zastosowaniach.
-
Router przemysłowy - obecnie również routery przemysłowe znacznie rozwinęły swoją pierwotną funkcjonalność. Poza obsługą sieci 4/5G, dzięki implementacji wydajnych procesorów ARM, router stał się również bramą IoT. Jest to rozwiązanie dużo skuteczniejsze niż gateway przemysłowy w przypadku aplikacji pracujących na terenach zewnętrznych np. stacje transformatorowe, stacje gazowe. Podobnie jak w wyżej wymienionym sprzęcie, producenci routerów przemysłowych często decydują się na implementacje systemu operacyjnego Linux. Sprawia to, że za pomocą jednego urządzenia możemy zbierać dane z procesu, przetwarzać je za pomocą dedykowanego software'u oraz przesyłać do zewnętrznych Data Center.

-
Komputery przemysłowe mini BoxPC - najpotężniejszy oręż w walce z centralizacją systemów. Wzrost zapotrzebowania na moc obliczeniową na brzegu aplikacji sprawił, że obecnie na rynku mamy nieprawdopodobnie duży wybór różnych jednostek. W zależności od naszych potrzeb możemy wybrać:
- kompaktowe modele bezwentylatorowe,
- rozwiązania posiadające dużą przestrzeń dyskową pozwalającą na przechowywania danych z wielu punktów pomiarowych (działające jako lokalne centra danych),
- ultra-wydajne obliczeniowo urządzenia oparte na najnowszych procesorach Intel Core i GPU Nvidia RTX, Tesla lub Quadro.
Nawet jeżeli działamy w silnie regulowanych branżach, takich jak: transport, branża militarna, możemy bez problemu dobrać IPC posiadający odpowiednie certyfikaty. Jest bardzo rozległa gałąź sprzętu; w naszym centrum przygotowaliśmy wiele wpisów, które pomagają zorientować się w rynku IPC.
Wzorce projektowe analizy brzegowej oraz najpopularniejsze zastosowania
Gdzie zatem implementuje się najwięcej rozwiązań brzegowych? Omówmy teraz kilka najpopularniejszych zastosowań samodzielnych rozwiązań Edge Computing lub wchodzących w skład Fog Computing.
Jeżeli chodzi o aplikacje wykorzystujące samodzielne systemy przetwarzania brzegowego, najczęstsze zastosowania to:
-
Rozproszone systemy pomiarowe - stosunkowo proste rozwiązanie, gdzie idea urządzeń brzegowych sprawdza się idealnie, ze względu na swoją architekturę. Często takie systemy są instalowanie w zakładach, których specyfika produkcji nie wymaga stosowania rozbudowanych systemów sterowania, a jedynie urządzeń pomiarowych, pozwalających na prostą kontrolę efektu procesu wykonywanego przez operatorów. Przykład takich obiektów możemy znaleźć w szeroko pojętej branży letniej - tartaki, miejsca zrywki, gdzie sprawdzane są parametry suszenia drewna. Ze względu na specyfikę takiej produkcji (rozległe obszary składowania pozbawione przyłącza elektrycznego, często słabe pokrycie zasięgiem GSM), dysponując prostymi urządzeniami internetu rzeczy oraz chmurowym rozwiązaniem do archiwizacji danych możemy znacznie zwiększyć produktywność zakładu i zmniejszyć ilość odrzutu drewna.
-
Zapewnienie bezpieczeństwa podczas pracy - przetwarzanie brzegowe sprawdzi się również w sytuacjach, gdzie działania pracowników powinny być monitorowanie pod kątem zachowania zasad BHP (branża budowlana, produkcja chemiczna). Zastosowanie Edge Computing sprawdza się szczególnie w oddalonych od infrastruktury miejscach pracy, gdzie z powodu opóźnień powodowanych przez łącze internetowe, Cloud Computing nie będzie w stanie zapewnić bezpieczeństwa. W takich aplikacjach, smart kamery lokalnie przetwarzają obraz w celu wykrycia czy pracownik posiada na sobie odpowiednie środki ochronne (np. maska, kask). Wykorzystując algorytmy machine learning pracujące bezpośrednio na podzespołach kamery możemy takie zadanie realizować z dużą dokładnością.
-
Predictive maintenance - niespodziewane awarie oraz przestoje w produkcji generują potężne straty dla przedsiębiorstwa. Coraz popularniejsze staje się wykorzystanie algorytmów diagnostycznych, które pozwalają przewidzieć awarie danego sprzętu. W tej technologii możemy wyróżnić dwa różne podejścia. Klasycznym sposobem jest wykonywanie pomiarów współrzędnościowych przez wykwalifikowanych pracowników, a następnie ich interpretacja. Tymczasem Edge Computing umożliwia analizę zebranych danych w czasie rzeczywistym. Większa liczba pomiarów pozwala na szybsze wykrywanie uszkodzeń w urządzeniu i prowadzenie skuteczniejszych działań serwisowych.
-
Smart agriculture - w dobie drastycznych zmian klimatycznych, należy poświęcić dużą uwagę produkcji rolnej. Dzięki wykorzystaniu rozwiązań Edge Computing jesteśmy w stanie prowadzić dokładne pomiary gleby oraz zintegrować system system z różnymi zewnętrznymi API (pogodowe, nasłonecznienia, jakości powietrza), co pozwala podnieść wydajność i jakość produkcji. Przykładem takiego rozwiąznia są np. smart siewniki i rozrzutniki nawozu, który dobierają wydatek materiału (ziarna lub nawozu), na podstawnie danych o kondycji gleby i historycznych wyników zbiorów z danego obszaru.
Bardziej złożone aplikacje IoT, poza analizą danych w czasie rzeczywistym, potrzebują ciągłej komunikacji z systemami centralnymi, które posiadają praktycznie nieograniczoną moc obliczeniową. W takich przypadkach sprawdzi się wzorzec projektowy Fog Computing. Przykładami takich zastosowań są:
-
Samochody autonomiczne - obecnie jedno z najpopularniejszych środowisk w których wykorzystuje się urządzenia brzegowe. Ośrodkiem obliczeniowym jest tutaj dedykowany komputer pokładowy samochodu lub zewnętrzna jednostka obliczeniowa w postaci IPC. Ze względu na dużą ilość zbieranych danych oraz specyfikę aplikacji, decyzje odnośnie krytycznych aspektów działania systemu muszą być podejmowane lokalnie, a dopiero rejestrowane zdarzenia, wobec których samochód podjął już jakieś działanie, jest dokładniej przetwarzana pod kątem uczenia maszynowego w centralnym systemie.
-
Transport/Fleet Management - nawet gdy pojazdy prowadzone są przez człowieka, implementacja Fog Computing niesie za sobą gigantyczne zyski dla przedsiębiorstwa. Możemy stworzyć zarówno małe systemy Edge, zbierające dane z pojazdów flotowych (lokalizacje, prędkość, zużycie paliwa, czas jazdy na tempomacie), jak i duży system zintegrowanej logistyki. Takie rozbudowane rozwiązanie pozwala na wytyczanie najbardziej optymalnej trasy przejazdu samochodu, integruje się z systemem wizualizacji w pojeździe i centrali, zawiera w sobie elementy predictive maintenence oraz automatycznej komunikacji z kontrahentami. Niektórzy producenci pojazdów ciężarowych (np. Scania, Volvo), tworzą własne oprogramowanie do zarządzania i prowadzenia kontroli pojazdu. Jednak w sytuacji gdy chcemy zunifikować komunikację w naszym systemie centralnym z różnymi pojazdami (tego samego typu ale innych producentów, lub zupełnie innych środków transportu), autorski system oparty na urządzeniach wykorzystujących przetwarzanie brzegowe, sprawdzi się lepiej.
Automatyka, OT i IT - nowe możliwości, zagrożenia i wyzwania
Wykorzystując najnowsze technologie możemy przenieść nasz proces na zupełnie inny poziom pod względem wydajności oraz kontroli. Jednak stworzenie takiego zdecentralizowanego systemu wymaga od nas połączenia wiedzy z automatyki - na etapie zbierania danych, Operation Technology (OT) - na etapie monitoringu, łączności i zabezpieczenia cybernetycznego, oraz IT - na etapie dokonywania analizy danych i architektury chmurowej.
Integracja systemów Edge Computing niesie ze sobą pewne wyzwania, których należy mieć świadomość, już na początku tworzenia koncepcji systemu.
Należy pamiętać, że wraz z rozbudowaniem funkcjonalności systemy, rośnie możliwość występowanie błędów oraz liczba wektorów ataków cybernetycznych. Wg. danych BG Network, obecnie 80% urządzeń IoT dostarczanych jest bez zainstalowanego/aktywowanego systemu uwierzytelnia i szyfrowania. Ponadto, sama charakterystyka zdecentralizowanej architektury zwiększa ryzyko wystąpienia ataku, szczególnie odbywającego się w sposób bezpośredniego kontaktu cyberprzestępcy z urządzeniem. Przykładowo, w systemach Edge pracujących w środowisku smart city, znacznie trudniej jest się zabezpieczyć przed nieautoryzowanym dostępem do urządzenia (a w konsekwencji jego pamięci), niż w w przypadku obwarowanego centrum danych. Oczywiście na rynku znajdziemy narzędzia i oprogramowanie, które może nas w dużym stopniu przed tym zabezpieczyć.
Pomimo tego, że Edge Computing rozwiązuje dużą ilość problemów związanych z ograniczeniami technologicznymi, stwarzają one kilka nowych wyzwań - głównie natury logistycznej. Obsługa techniczna takiego systemu może okazać się znacznie trudniejsza, szczególnie jeżeli aplikacja pracuje w odległych, trudno dostępnych lub pozbawianych odpowiedniej kadry pracowniczej miejscach.
Podsumowując, skalowanie rozwiązań edge computing pochłania więcej zasobów niż rozbudowa centralnej bazy danych działającej w zabezpieczonym budynku. Mimo to, Edge Computing to naprawdę ciekawa i rozbudowana część systemów automatyki przemysłowej. Co jednak ważniejsze, przy odpowiedniej implementacji, przynosi realne korzyści dla praktycznie każdego sektora przemysłu.



















