Przetwarzanie danych w systemie SCADA ICONICS

- Zakłady przemysłowe
- Górnictwo
- Energetyka
Spis Treści
System SCADA od ICONICS został wyposażony w szereg narzędzi do przetwarzania oraz analizy danych - zarówno pojedynczych zmiennych, jak i całych tabel. Z naszym systemem możesz poszerzyć funkcjonalność SCADy o dodatkowe aspekty dotyczące generowania zestawień, kontekstowych porównań oraz analiz działalności przedsiębiorstwa.
Bez programowania skonfigurujesz własne źródła danych Business Intelligence (BI) oraz potrzebne operacje na nich wykonywane. Pozwoli Ci to na uzyskanie kompletnego systemu SCADA + MES zawartego w jednym oprogramowaniu.
Poniżej zamieszczono szereg lekcji dotyczących konfiguracji poszczególnych funkcji.
Analiza zestawów danych Business Intelligence dzięki BI Server
AnalytiX-BI daje możliwość spójnego wizualizowania danych. Narzędzie pozwala na łączenie danych z wielu źródeł, nadawania im relacji oraz ich analizę.
Serwer BI umożliwia użytkownikowi konfigurację danych Buisness Inteligence (BI) poprzez import danych z wielu źródeł do Modelu Danych (Data Model). Model danych organizuje je w zbiór tabel (zestawów danych) powiązanych zależnościami. Dane z różnych źródeł mogą być zawarte w tej samej tabeli jako podstawa do obliczanych wartości w kolumnach. Taka organizacja danych pozwala użytkownikowi na wykorzystanie elementów wizualnych BI, szczególnie w ramach modułu graficznego KPIWorX. BI Server został stworzony, aby zapewnić użytkownikom systemu GENESIS64:
- Zwiększoną dostępność danych,
- Przetwarzanie danych,
- Modelowanie i kontekstualizację danych,
- Przyśpieszenie odczytu danych dzięki ich buforowaniu,
- Rozwiązanie problemu fragmentyzacji wizualizacji.
Jak działa BI Server?
Serwer BI jest elementem wizualizacji i analizy Business Intelligence. Dostarcza on narzędzia do modelowania zbiorów danych, które umożliwiają wydobycie cennych informacji z surowych danych. Łączność ze źródłami danych konfigurowana jest w Data Flows.
W najprostszej postaci, Data Flows odczytuje dane ze źródła i normalizuje je do zbioru danych. Źródła danych obejmują te historyczne (nieprzetworzone i zagregowane), alarmy archiwalne, informacje o usterkach (FDD) oraz ogólne zbiory danych (GridWorX i Web Services). W ramach Data Flow możliwe jest również dalsze przetwarzanie danych poprzez tworzenie kryteriów filtrowania wierszy, usuwanie niechcianych kolumn lub tworzenie kolumn obliczeniowych na podstawie wyrażeń.
| Po skonfigurowaniu źródeł danych, można utworzyć modele danych (Data Models), które podobne są do bazy danych SQL i zasadniczo są zbiorem tabel, relacji i widoków. Tabele są połączone z Data Flows, które zapewniają schemat i dane dla samej tabeli. Po zdefiniowaniu tabel można utworzyć powiązania między nimi w ramach modelu danych. Widoki (Views) działają jak wirtualne tabele, dzięki czemu użytkownicy mogą definiować i nazywać często używane niestandardowe zapytania. |
Konfiguracja BI Serwer
Pierwszym krokiem jest skonfigurowanie Data Flow. Przedstawiony poniżej wpis będzie opierał się na analizie danych historycznych pochodzących z przykładowej konfiguracji modułu archiwizacji Hyper Historian.
Konfiguracja Data Flow
Zanim zaczniemy, upewnij się że usługa Hyper Historian jest włączona, oraz skonfigurowane są zmienne w Hyper Historian.
- Otwórz Workbench i rozwiń moduł AnalitiX by znaleźć BI Server.
- Kliknij PPM na Data Flows i stwórz nowy folder o nazwie Sygnaly
- Podobnie jak w poprzednim kroku, w nowo stworzonym folderze stwórz Data Flow o nazwie Nazwy.
- Po stworzeniu Data Flow ukaże się okno, w którym dodaje się źródła danych.
- W sekcji Steps kliknij Click here to add a new step, a następnie wybierz Dimensions > Historical Tags.
- Za pomocą Click to add multiple tags dodaj tagi historyczne z folderu Various Signals znajdującego się w Historical Data > Hyper Historian > Configuration. Po dodaniu tagów, w sekcji Data Flow Preview pojawi się podgląd pobranych.
- Dodaj kolejny Data Flow, tym razem o nazwie Dane. W sekcji Steps kliknij Click here to add a new step i wybierz Historical Data > Hyper Historian Raw Data.
- Tak jak w kroku 6. dodaj zmienne oraz określ daty początku i końca zakresu, z którego dane będą pobierane.
- Po pobraniu danych istnieje wiele możliwości interakcji np. filtrowanie wierszy, czy też dodanie nowej kolumny.

Konfiguracja Data Model
Model Danych (Data Model) służy do definiowania relacji między tabelami Data Flow.
- Utwórz nowy model danych o nazwie Sygnaly klikając PPM na Data Models wybierając New Data Model.
- W nowo stworzonym modelu danych zaznacz okienko online i zaakceptuj zmiany.
- Następnie na modelu danych Sygnaly kliknij PPM i dodaj tablicę danych (Data Table).
- W nowo stworzonym obiekcie, w oknie Data Source dodaj wcześniej stworzony Data Flow Nazwa.
- Ponownie wykonaj krok 4. dodając Data Flow Dane.
- Powróć do modelu danych Sygnaly, następnie przeciągnij górną część tabeli Nazwy na górę tabeli Dane. Upewnij się że przeciągasz Dane na Nazwy!
- Po połączeniu tabel otworzy się edytor relacji. Przy poprawnej konfiguracji powinno się wyświetlić Primary key table jako Nazwy oraz Foreign key jako Dane. Stwórz nowy element i z list rozwijanych wybierz kolumny PointName.
- Kliknij Ok i zaakceptuj zmiany.

Konfiguracja Data Views
Data Views używane do wstępnej konfiguracji zapytań, które chcesz często używać w GridWorX Viewer.
- By stworzyć nowy Data View kliknij PPM na modelu danych Sygnaly i wybierz Add Data View. Nadaj obiektowi dowolną nazwę.
- W oknie Data Source wklej następujące zapytanie:
SELECT Nazwy.Name, Sum(Dane.Value) FROM Nazwy INNER JOIN Dane ON Nazwy.PointName = Dane.PointName
- Kliknij poza oknem Data Source aby zobaczyć podgląd. Następnie zaakceptuj zmiany.
Tak skonfigurowany zestaw danych BI może być wykorzystywany w wizualizacji z użyciem GraphWorX oraz KPIWorX.
Wykorzystanie zestawów danych Business Intelligence w wizualizacji KPIWorX
Zestawy danych Buisness Inteligence bez ich atrakcyjnej, graficznej wizualizacji są mało przydatne. Ten wpis omówi jak efektywnie użyć zestaw danych z BI Server.
Konfiguracja KPIWorX
By przejść do KPIWorX należy włączyć GraphWorX64 w trybie runtime, następnie na wstążce wybrać ikonę podpisaną KPIWorX lub właczyć dowolną przeglądarkę internetową obsługującą HTML5 i wpisać adres:
(lub adres IP komputera w miejsce localhost, na którym zainstalowany jest pakiet Genesis64). Po przejściu do KPIWorX ukaże się nam okno konfiguracji, w którym możemy konfigurować dowolnie układ ekranu wizualizacji. Tutaj także dodajemy widżety wizualizacji. Konfiguracja odbywa się na zasadzie przeciągnij i upuść, z lewej strony okna przeciągamy dane, a z prawej symbole i widżety. Przejdźmy do konfiguracji:
- Przeciągnij widżety na ekran wizualizacji jak zaprezentowano poniżej.

- Z lewej strony ekranu w drzewie zasobów przejdź do My Computer> AnalitiX> BI Server> Data Models> Sygnaly. Następnie z zakładki Nazwy przeciągnij element Display Name na widżet Filter.
- Przejdźmy do konfiguracji Pie. Przeciągnijmy na niego kolejno DisplayName z Nazwy, oraz Value z Dane. Mając zaznaczone Pie przełącz zakładkę z prawej strony okna na zakładkę Widget Setting. Jak widać konfigurator automatycznie skonfigurował nam wartości wsadowe jako suma wartości, można jednak zmienić to rozwijając listę.
- Następnie przejdźmy do konfiguracji Data Diagram. Dodajmy sumę Value do Value, DisplayName do Columns oraz Timestamps do Rows.
- Kolejnym elementem, który skonfigurujemy będzie Categorical Chart. Przeciągnij kolejno na ten element Timestamp oraz dwukrotnie Values. Następnie z listy rozwijanej wybierz wartość średnią (Avg of Values) oraz maksimum (Max of Values). Tak skonfigurowany wykres umożliwi nam filtrowanie wartości po datach. Wejdź w tryb prezentacji aby sprawdzić działanie funkcjonalności drill down. By przejść w głąb źródeł danych należy dwukrotnie kliknąć LPM na interesujący nas słupek danych. Jak widać filtrowanie danych ma wpływ na cały ekran z danymi.
- Ostatnim elementem, który pozostał do konfiguracji jest to Tree Map. Przeciągnij DisplayName oraz Values. Możesz dowolnie zmienić typ agregacji np. z Sum na Avg.
- Następnie przejdź do trybu prezentacji i sprawdź efekty konfiguracji. Sprawdź jak działa wizualizacja, a następnie sprawdź inne opcje konfiguracji, których nie omówiłem w tym wpisie. Zmieniaj konfigurację i sprawdź jakie możliwości daje wizualizacjia KPIWorX.





Obliczanie daty w systemie SCADA
Zobacz jak proste jest obliczanie daty i czasu w systemie SCADA od ICONICS, z wykorzystaniem szeregu wbudowanych gotowych funkcji.
Obliczanie daty w systemie SCADA dzięki gotowym funkcjom
Pakiet oprogramowania SCADA - GENESIS64 od firmy ICONICS wyposażono w szereg wbudowanych funkcji w celu obliczania daty i czasu. Funkcje te mogą zwracać zarówno datę i czas, jak i inne informacje im towarzyszące. Takimi dodatkowymi informacjami może być na przykład:
- numer dnia w danym tygodniu zwracany na podstawie podanej daty,
- data pierwszego dnia roku, wskazanego przez użytkownika.
Obliczanie daty za pomocą gotowych funkcji wykorzystuje się w systemie SCADA zarówno w modułach:
- HyperHistorian (za wyjątkiem wersji Express);
- Expressions - narzędzie dostępne w Workbench; służy do budowania własnych wyrażeń;
- jak i nawet bezpośrednio w GraphWorX - module pozwalającym na projektowanie graficznych interfejsów użytkownika.
Dlatego, że liczba dostępnych funkcji jest duża (tak jak możliwości które niosą one ze sobą), podzielono ten wpis na dwie części.
Pierwszą z nich będzie krótka prezentacja tychże funkcji w module GraphWorX. Pokazano w niej, w jaki sposób uzyskać do nich dostęp, w celu użycia ich w pojedynczym ProcessPoint (okienku wyświetlania danych). W tym miejscu wywoływano je pojedynczo, aby zwiększyć przejrzystość prezentacji.
Kolejna część wpisu pokaże natomiast sposób wykorzystania tych funkcji w praktyce, w nieco bardziej skomplikowanej konfiguracji. Efektem będzie dodanie do modułu Expressions w Workbench własnego wyrażenia obliczającego numer tygodnia. Obliczenia będą przebiegać zgodnie z wytycznymi Głównego Urzędu Miar, które można podejrzeć tutaj. Co więcej, numer tygodnia będzie obliczany na podstawie daty podawanej na bieżąco przez użytkownika - parametru wejściowego. Tak więc dane wyrażenie będzie można używać wielokrotnie, w różnych kontekstach - na przykład w module GraphWorX.
Proste obliczanie daty za pomocą funkcji w GraphWorX
W tej sekcji pokazano jak uzyskać dostęp do zestawu funkcji zwracających datę i czas w systemie SCADA ICONICS. Lista tych funkcji jest długa, więc wybrano i opisano tylko kilka przykładów. Przykłady te podzielono na 2 kategorie.
Funkcje nie przyjmujące żadnych argumentów
Przykładami funkcji, które nie przyjmują żadnych argumentów mogą być:
- now() - zwraca obecną datę i czas (dla lokalnej strefy czasowej); co więcej, zwraca ją tylko raz, w momencie wywołania wyrażenia - na przykład przy odświeżeniu ekranu; istnieje analogiczna funkcja - utcnow() zwracająca uniwersalną datę i czas;
- yday() - automatycznie pobiera aktualną datę z systemu i zwraca datę wczorajszą z czasem ustawionym na północ (12 AM); analogiczną funkcją jest today() zwracająca dzisiejszą datę.
Funkcje przyjmujące argumenty
Natomiast funkcje przyjmujące argumenty (najczęściej jest to inna data, choć czasem też liczba), to na przykład:
- currentdatetime(RefreshRate) - zwraca aktualną datę i lokalny czas, z tym, że odświeża swój wynik z okresem podanym jako argument (w milisekundach);
- year(DateTime) - przyjmuje parametr będący datą i zwraca liczbę z przedziału 0-9999 będącą rokiem zawartym w tej dacie;
- yearday(DateTime) - podobnie jak wyżej, przyjmuje datę jako argument; na jej podstawie zwraca numer mówiący, który to dzień w danym roku;
- byear(DateTime) - zarówno przyjmuje, jak i zwraca zmienną będącą datą; zwrócona data reprezentuje pierwszy dzień roku wynikającego z parametru wejściowego; czas w zwróconej dacie ustawiony jest na północ (12 AM).
Domyślnym formatem dla dat zwracanych przez funkcje jest "MM / DD / YYYY". Daty podawane jako parametry wejściowe mogą być natomiast:
- wynikiem działania innych funkcji - dopuszczalny jest na przykład zapis: byear( now() );
- łańcuchem znaków wpisywanym ręcznie lub przekazywanym poprzez Alias; wtedy najlepiej posłużyć się formatami:
- "YYYY - MM - DD" lub "YYYY/MM/DD",
- "MM-DD-YYYY" lub "MM/DD/YYYY".
Obliczanie daty na przykładowym ekranie SCADA
W tej sekcji zamieszczono krótkie wideo prezentujące w praktyce wyżej opisane funkcje.
| W celu ich użycia można posłużyć się obiektem typu ProcessPoint. Następnie w jego konfiguracji należy otworzyć okno pomocnicze, za pomocą przycisku przy opcji "DataSource". Okno to zawiera zakładkę "Expression" służącą do budowania swoich wyrażeń na bieżąco w GraphWorX. Użytkownik ma tam dostęp między innymi do opcji "Functions" prowadzącej do listy wszystkich gotowych funkcji. |
Prezentacja funkcji obliczających datę i czas w GraphWorX |
Przykład zastosowania wbudowanych funkcji ICONICS
Tak, jak zostało to opisane w pierwszej sekcji, ta część wpisu poprowadzi czytelnika przez proces przygotowania własnego uniwersalnego wyrażenia. Będzie ono zwracało numer tygodnia w danym roku na podstawie daty, którą użytkownik przekazuje jako argument wejściowy. Numer tygodnia obliczany oblicza się zgodnie z wytycznymi Głównego Urzędu Miar.
Do zbudowania własnego wyrażenia (nieco bardziej skomplikowanego niż dotychczasowe przykłady) posłuży narzędzie "Expressions" dostępne w programie konfiguracyjnym - Workbench.
Dodatkowe potrzebne funkcje
Oprócz tych wymienionych wcześniej, będą potrzebne poniższe dodatkowe funkcje operujące na datach:
- weekday(DateTime) - przyjmująca określoną datę i czas, a zwracająca numer z zakresu 0-6, będący numerem podanego dnia w tygodniu; przy czym: 0 - niedziela, 6 - sobota.
- totaldays(TimeSpan) - przyjmująca zmienną reprezentującą odstęp czasu (typu TimeSpan) - np "1.20:40:30" (1 dzień, 20 godzin, 40 minut, 30 sekund); zwraca ona liczbę dni (w ułamku) odpowiadającą temu odstępowi czasu - tutaj będzie to około 1.86;
- fromdays(number_of_days) - pozwala na dodanie do zmiennej typu DateTime (daty) określonej liczby dni (number_of_days).
Ostatnia używana funkcja jest czysto matematyczna i nosi nazwę floor(arg). Używa się jej w celu usunięcia z ułamka wartości po przecinku - w przypadku liczb dodatnich - do zaokrąglenia w dół.
Znając już wszystkie potrzebne funkcje, można zabrać się za konfigurowanie wyrażenia w systemie SCADA odpowiedzialnego za obliczanie numeru tygodnia.
Narzędzie "Expressions" w programie Workbench
| Na poniższym wideo pokazano, w jaki sposób dodać nowe wyrażenie do programu Workbench - pod zakładką "Expressions". Dodatkowo, skonfigurowano dla niego parametr wejściowy - "DATE" przekazujący datę do dalszych obliczeń. Aby użyć go w oknie do pisania skryptów, należy otoczyć go znakami: "<< i >>". W tym przypadku będzie to: "<<DATE>>" . |
Dodanie nowego wyrażenia z parametrem w Workbench |
Wyrażenie obliczające numer tygodnia
Na samym początku budowy algorytmu należy zdać sobie sprawę, że zgodnie z wytycznymi Głównego Urzędu Miar (a przede wszystkim normą ISO), istnieją lata posiadające 52 lub 53 tygodnie. Warunek sprawdzający, czy dany rok jest "długi" można odczytać z wielu źródeł i wygląda ona następująco.
Jeśli wyrażenie:
p(y) = y + floor(y/4) - floor(y/100) + floor(y/400)
podzielone modulo przez 7 da wynik:
- 4 dla zmiennej y równej numerowi danego roku lub
- 3 dla y równej numerowi danego roku pomniejszonemu o 1,
to dany rok jest rokiem "długim". Taki też warunek należy jako pierwszy wprowadzić do wyrażenia w Workbench. W przypadku oprogramowania SCADA GENESIS64 ma on postać jak niżej.
Cały kod będzie udostępniony w formie pliku tekstowego w podsumowaniu.
| Należy pamiętać, że w przypadku omawianego zadania dysponuje się jedynie parametrem <<DATE>>, który przechowuje pełną datę wprowadzaną przez użytkownika. Aby uzyskać numer roku należy użyć funkcji "year()". |
|
Można zauważyć, że jeśli rok jest "długi" to zaczyna się w środę lub czwartek. Aby więc policzyć numer tygodnia dla takiego roku, wystarczy:
- wziąć numer danego dnia w tym roku - funkcja yearday(),
- zwiększyć go o 1, jeśli rok zaczynał się w środę lub o 2 - jeśli w czwartek (dzięki temu pierwszy poniedziałek w nowym roku będzie już częścią 2. tygodnia),
- podzielić modulo 7 otrzymany wynik oraz odrzucić część ułamkową (opcjonalnie dodać 1 jeśli chcemy numerować tygodnie od 1).
Powyższe kroki spełnia następujące równanie.
floor( ( yearday("<<DATE>>") + weekday( byear("<<DATE>>") ) - 2 ) /7 ) + 1

Dalsze postępowanie (dla lat "krótkich") zależy od tego, czy bieżący rok zaczął się przed czwartkiem. Jest to równoznaczne z tym, czy tydzień zawierający pierwszy dzień b.r. jest pierwszym tygodniem tego roku, czy ostatnim poprzedniego.

Jeśli obecny rok rozpoczął się przed czwartkiem i jest rokiem "krótkim", to znaczy, że jego ostatni dni należą już do pierwszego tygodnia roku kolejnego. Jak sprawdzić czy podana data nie dotyczy właśnie tych ostatnich dni?
Jeśli takie samo wyrażenie, jak to zwracające wynik dla roku "długiego", zwróci tu wynik mniejszy niż 53 (krótki rok nie może mieć 53 tygodni), to znaczy że może być ono użyte do wyliczenia numeru tygodnia. Jeśli zaś zwróci 53, to tak na prawdę prawidłowym numerem tygodnia jest 1, gdyż jest to już pierwszy tydzień kolejnego roku.
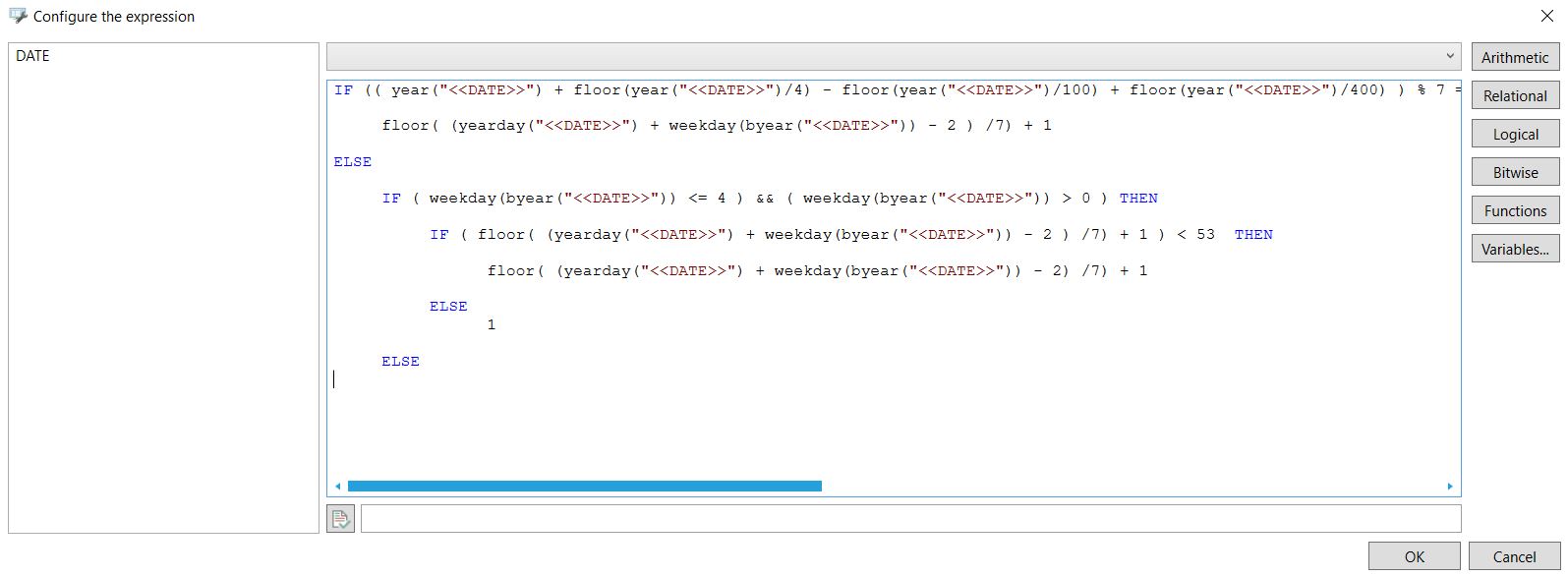
Dla lat, które zaczynały się w dzień tygodnia po czwartku (tydzień zawierający ich początek jest ostatnim tygodniem roku poprzedniego) należy wykonać podobne rozumowanie. Teraz jednak należy sprawdzić, czy wprowadzona jako parametr data nie dotyczy właśnie tych początkowych dni.
Można tego dokonać poprzez weryfikację 3 par warunków:
- obecny dzień to co najwyżej trzeci dzień roku, a rok zaczął się w piątek;
- dzień z podanej daty to co najwyżej drugi dzień roku, a rok zaczął się w sobotę;
- obecny dzień to pierwszy dzień roku, a rok zaczął się w niedzielę.
Sprawdzenie warunków następuje za pomocą funkcji yearday(), weekday(), byear().
Jeśli choć jeden z powyższych warunków jest prawdziwy, to numer tygodnia jest następujący:
- 53 - jeśli poprzedni rok rozpoczął się przed czwartkiem;
- 52 - jeśli po czwartku.
Jeśli wszystkie powyższe warunki są fałszywe, numer tygodnia oblicza się z poniższego wzoru.
floor(( yearday("<<DATE>>")-weekday( byear("<<DATE>>") )%5-weekday( byear("<<DATE>>") )%3 - 2) /7)+1
Ideą tego wzoru jest, aby od numeru dnia w roku odejmować: 2 - jeśli pierwszy dzień roku to niedziela, 3 - sobota, 4 - piątek.

Prezentacja rezultatów
Proste przekazywanie parametru do wyrażenia
Aby szybko przekazywać datę podawaną przez użytkownika do stworzonego wyrażenia można, zastosować następujący sposób.
Pierwszym krokiem jest dodanie do ekranu SCADA elementu ProcessPoint wraz z przypisaną do niego lokalną zmienną tekstową oraz odblokowanie opcji wprowadzania danych.
| Następnie można dodać przycisk zapisujący wartość tej zmiennej do Aliasu - globalnego lub lokalnego. Dzięki Aliasom można w prosty sposób przekazać dowolny ciąg znaków jako parametr wejściowy do wyrażenia. Całość powyższych działań prezentuje krótkie wideo. |
Przekazywanie parametru do wyrażenia |
Sprawdzenie poprawności algorytmu
|
Mając przygotowany ProcessPoint do wpisywania dat, oraz pozostałe komponenty do przekazywania ich jako parametr wyrażenia, można przejść do testowania działania algorytmu. Poniżej znajduje się kompletny kod wyrażenia zaprojektowanego na potrzeby tego artykułu.
|
Prezentacja działania wyrażenia na numer tygodnia w roku |
Tworzenie złożonych operacji na danych w systemach SCADA
GENESIS64 pozwala nie tylko na odczyt różnych danych i prezentację ich wartości. Możliwe jest też planowanie złożonych operacji zależnych od informacji wejściowych.
Wykorzystywane narzędzie
Zdanie konfigurowania algorytmów obróbki danych, często zależnych od samych danych wejściowych, realizowane jest za pomocą narzędzia BridgeWorX. Jak wszystkie narzędzia pakietu GENESIS64, jest ono konfigurowane z poziomu Workbench. Tworzenie schematów obliczeniowych bardzo przypomina tworzenie schematów blokowych. Użytkownik ma do dyspozycji pewien zestaw bloków funkcyjnych, które może odpowiednio konfigurować oraz łączyć ze sobą.
Konfiguracja BridgeWorX
Konfiguracja narzędzia odbywa się w zakładce "Bridging", którą można znaleźć w sekcji "Project Explorer" w Workbench. Kolejne kroki są następujące.
- Po kliknięciu PPM na folder "Transactions" można wybrać opcję "Add Configuration" lub skorzystać z już istniejącej w tym folderze.
- W przypadku dodawania nowej, należy uzupełnić pola takie jak: nazwa konfiguracji; liczba wątków (projektów), które zawiera - "Number of Threads" oraz czas, po upływie którego anuluje się pracę wątku - "Cancel Timeout";
- opcjonalne jest skonfigurowanie archiwizacji plików z informacjami o przebiegu wykonywanych algorytmów w zakładce "Archiving".
- Przy tworzeniu nowej konfiguracji należy pamiętać o zaznaczeniu okno "Active Configuration" w zakładce "Generic Properties".
- Następnie należy kliknąć PPM na żądaną konfigurację i wybrać "Add Transaction" - projekt, który będzie podpięty pod wybraną konfigurację.
- W zakładce "Transaction Settings" nowo otworzonego okna kluczowe jest tylko zaznaczenie okienka "The transaction is enabled". Zakładka "Transaction Execution" służy do definiowania zmiennych, które będą wyzwalać wykonywanie się projektowanego algorytmu. Nie będzie jednak ona użyta w omawianym projekcie.
- Ostatnim krokiem jest utworzenie szablonu projektu w zakładce "Transaction Settings" w sekcji "Transaction Template". Dokonuje się tego przez wybranie ikonki "plusa" po prawej stronie pola "Selected Template" lub przez kliknięcie PPM na folder "Templates" (Project Explorer -> Bridging).
Tworzenie szablonu operacji na danych
Po wykonaniu kroku 6 poprzedniego akapitu powinno pojawić się tak wyglądające okno.
|
W przypadku, gdy niewidoczny jest pasek z blokami funkcyjnymi zaznaczony z lewej strony, należy wybrać opcję zaznaczoną strzałką.
W zakładce "Template Diagram" tworzony jest schemat blokowy. Zakładka "Settings and Parameters" odpowiada za deklarowanie parametrów dostępnych przy tworzeniu szablonów, jednak w omawianym przypadku nie będzie wykorzystana. |
Zdj. 1 |

Działanie BridgeWorX najlepiej zobrazuje przykład. Załóżmy, że obsługiwany jest pewien prosty system. Z poziomu GraphWorX, operator podaje pewną wartość która wpływa na pracę urządzenia. Jeśli wartość ta jest większa niż (załóżmy) 300, urządzenie nie będzie pracowało poprawnie. Należy tak zaprojektować system, aby uniemożliwił uruchomienie urządzenia, gdy podany parametr wynosi więcej niż 300. Ponadto, w przypadku nieprawidłowej wartości parametru, wysłany będzie mail ostrzegawczy na wcześniej skonfigurowany adres.
Aby wykonać postawione wyżej zadanie należy:
- Z listy bloków funkcyjnych wybrać "Real Time Input", przeciągnąć go nad siatkę i dołączyć do bloku startowego. Ten blok odpowiada za odczyt wprowadzanego przez operatora parametru.
- W oknie konfiguracji bloku, po prawej stronie, należy w zakładce "Data Sources" dodać odpowiednią zmienną przechowującą wartość parametru. Na potrzeby symulacji niech będzie to: @sim64:Double.Static("Zmienna1").Value.
- Kolejnym krokiem jest przeciągnięcie elementu "Condition" i dołączenie do niego wyjścia elementu poprzedniego. "Condition" odpowiada za sprawdzenie danego warunku.
- W oknie konfiguracji bloku, w zakładce "Other Settings" należy wybrać "Edit Expression". Następnie:
- wybrać "Previous Activity Output" (lewy górny róg) i do ukazanego w okienku wyrażenia dopisać: " < 300", co symbolizuje warunek.
- w argumentach wygenerowanego wyrażenia zamienić Row[index] na Row[0] oraz Col[indexOrN] na Col[1]. (Ma to związek z definicją zmiennej SCADA - "tag'u". Na wyjściu poprzedniego bloku w ogólności pojawia się zestaw tagów. Row[0] symbolizuje pierwszą ze zmiennych (w tym przypadku jedyną). Każdy tag to zestaw danych przechowywanych w kolumnach. Pierwsza kolumna to nazwa tag'u, druga to wartość zmiennej itd... Stąd zapis: {{PrevActivityOutput:Row[0].Col[1]}} < 300.)
- Kolejny potrzebny blok to "Real Time Output". Należy podpiąć do niego pierwsze z wyjść elementu "Condition", odpowiadające spełnieniu warunku. W oknie konfiguracji bloku w zakładce "Data Sources" w polu "Point Name" należy podać adres zmiennej, która ma zostać nadpisana, natomiast w polu "Output Expression" należy podać działanie, którego wynik zostanie zapisany do zmiennej. W omawianym przypadku adres to: @sim64:Bool.Static("Zmienna2").Value, a działanie: x=1. Blok ten odpowiada za uruchomienie urządzenia.
- Drugie wyjście elementu "Condition" musi zostać połączone z elementem "Send Email". W oknie ustawień bloku "Send Email", w zakładce "AlertWorX Configuration", w polu point name, należy wpisać: Alert:\SendEmail (zmienną tą można również wyszukać w okienku Data Browser: MyComputer ->AlarmsAndNotifications->AlertWorX->SendEmail() ). Aktywuje ona skonfigurowany węzeł E-Mail w zakładce AlertWorX w Workbench. To, jak skonfigurować węzeł E-mail zamieszczone jest w tym wpisie. Jedyna różnica względem podanego artykułu polega na zaznaczeniu opcji "Receive commands on this node" w oknie konfiguracji węzła E-Mail.
- Element "Send Email" wykorzysta jedynie dane dostępu do skrzynki pocztowej ze wskazanego węzła E-Mail w AlertWorX'ie w celu wysłania z niej wiadomości. To, na jaki adres ją wyśle, z jakim tematem i treścią zależy od sposobu, w jaki użytkownik uzupełni kolejne pola ("To adress", "Subject", "Message") w oknie ustawien "Send Email". Pola te mogą zawierać zarówno tekst wpisany z klawiatury, jak i wyrażenia dynamiczne konfigurowane za pomocą opcji "Edit Expression".
- Wyjście elementu "Send Email" należy połączyć z blokiem "Real Time Output", skonfigurowanym tak jak w punkcie 5, z tą różnicą, że teraz zapisywane działanie to x=0.
- Do elementu z punktu 5 i 8 należy podpiąć znacznik końca algorytmu. Najważniejsze kroki powyższych działań i efekt końcowy przedstawiają zdjęcia:
|
Ustawienia AlertWorx |
BridgeWorX - Output |
BridgeWorX - SendEmail |
|||



Testowanie aplikacji
Aby przetestować działanie aplikacji należy:
- Upewnić się że konfiguracje węzła E-Mail w AlertWorX oraz Szablonów w BridgeWorX są zapisane. Po ostatecznym skonfigurowaniu AlertWorX zalecane jest ponowne uruchomienie serwera E-Mail (Wyłączenie i załączenie ikony sygnalizacji świetlnej na górnym pasku narzędzi Workbench w zakładce "Home" w sekcji "Service", która pojawia się po wybraniu AlertWorX'a w oknie Project Explorer).
- W GraphWorX64 dodać 3 obiekty typu "ProcessPoint". Dla dwóch odblokować zapis do zmiennej (parametr "Data Entry" w ustawieniach dynamicznych musi mieć wartość "True").
- Do dwóch w/w obiektów jako źródła danych dodać: @sim64:Double.Static("Zmienna1").Value oraz zmienną odpowiedzialną za uruchomienie algorytmu BridgeWorX. W ogólnym przypadku ścieżka do zmiennej to: bwx:Nazwa_Transakcji_W_BridgeWorX/@@Execute. Może ona zostać wyszukana w Data Browser (MyComputer->Bridging->NazwaTransakcji).
- Do trzeciego obiektu "ProcessPoint" dodać jako źródło danych: @sim64:Bool.Static("Zmienna2").Value .
Teraz można testować zachowanie się układu poprzez podawanie różnych wartości zmiennej "Zmienna1" i zapisywanie "1" do bwx:Nazwa_Transakcji_W_BridgeWorX/@@Execute, a następnie odczytywanie, jak zmienia się wartość zmiennej "Zmienna2" oraz sprawdzanie powiadomień w podanej skrzynce pocztowej. Efekty przedstawia poniższy filmik.
Funkcjonalność BridgeWorX64 w systemie SCADA - GENESIS
Lista możliwości BridgeWorX64 jest długa. Wszystkie z dostępnych bloków funkcyjnych znajdują się na pasku zaznaczonym na Zdjęciu 1. Do najciekawszych należą: czytanie plików CSV, zestawów danych, historycznych alarmów, zapisywanie wartości do dynamicznego tagu, zapisywanie do plików CSV oraz XML, wprowadzanie opóźnienia, zmiana lokalizacji plików czy generowanie raportów.
BridgeWorX64 pozwala również na tworzenie własnych statycznych zmiennych lokalnych, widocznych tylko dla narzędzia BridgeWorX oraz statycznych jak i dynamicznych zmiennych globalnych. Służy do tego zakładka "Variables" (Workbench Project Explorer -> Bridging).
Elmark Automatyka udostępnia wersję demo oprogramowania GENESIS64 w celu osobistego przetestowania funkcjonalności pakietu. Skontaktuj się z nami na ICONICS@elmark.com.pl, aby porozmawiać o zastosowaniu naszych produktów w Twojej aplikacji.
Produkty powiązane




Skontaktuj się ze specjalistą Elmark
Masz pytania? Potrzebujesz porady? Zadzwoń lub napisz do nas!


















