
Prosty odczyt danych JSON z pliku do systemu SCADA ICONICS
Dowiedz się na przykładzie prostego projektu, jak prowadzić automatyczny odczyt danych JSON (z plików) oraz ich import do systemu SCADA.
Wykorzystywane zasoby
W celu wykonania powyższego zadania użyjemy wymienionych niżej narzędzi. Są to:
|
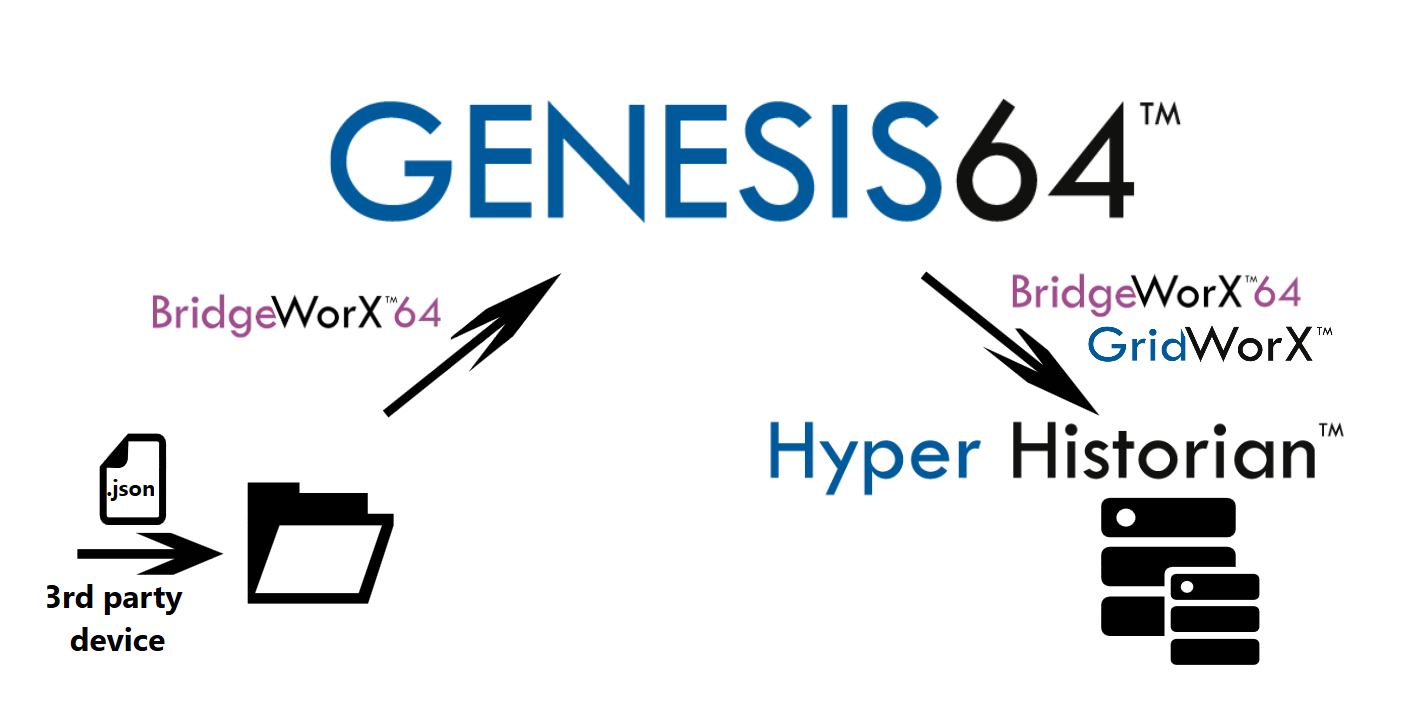 Odczyt danych JSON i ich import do bazy danych systemu SCADA ICONICS - schemat Odczyt danych JSON i ich import do bazy danych systemu SCADA ICONICS - schemat |
Dostosowanie ustawień narzędzia GridWorX
Jak już zostało to opisane, GridWorX pozwala na obsługę elementów (Data Manipulators), które wykonują zdefiniowane przez użytkownika zapytania/procedury na bazach danych. Pierwszym etapem konfiguracji jest więc dodanie Data Manipulatora, który w ostatecznym rozrachunku wprowadzi dane JSON do bazy Hyper Historian.
KOD PROCEDURY SKŁADOWANEJ SQL [KLIK]
Więcej informacji na temat dodawania własnych procedur do baz danych MS SQL Server oraz ich integracji z narzędziami pakietu GENESIS64 znajduje się w poniższym wpisie, w sekcji "Import danych za pomocą HH SQL Query Engine".
Konfiguracja odpowiedniego trigger'a
|
Dodany niżej trigger reaguje na pojawienie się określonego pliku w podanej przez użytkownika lokalizacji. Dodatkowo skonfigurowano go tak, aby wykrywał sytuację w której: plik zmienia swoją objętość, zmienia się również data jego ostatniej modyfikacji. Trigger ten można następnie wykorzystać do wyzwalania algorytmu w konfiguracji narzędzia BridgeWorX. Przykładową konfigurację trigger'a (wszystkie opcje, jakie należy dostosować) przedstawia poniższe zdjęcie. |
 Konfiguracja triggera wyzwalającego działania BridgeWorX Konfiguracja triggera wyzwalającego działania BridgeWorX |
Algorytm w BridgeWorX
Dlatego, że wpis ten jest poświęcony konkretnemu zastosowaniu narzędzia BridgeWorX, pominięto tu podstawy dodawania nowego szablonu algorytmu, czy dostosowywania opcji jego wykonywania przez system.
Jeśli jest to Twoje pierwsze spotkanie z tym narzędziem, w innym artykule na naszym blogu (podlinkowanym niżej) znajdziesz podstawy konfiguracji BridgeWorX. Znajdują się one w sekcji "Tworzenie złożonych operacji na danych w systemach SCADA"
Opis dostosowywania BridgeWorX na potrzeby importu danych do Hyper Historian rozpocznie się tu natomiast od tworzenia nowego szablonu algorytmu.
Szablon algorytmu - blok funkcyjny odczytu danych JSON
|
Bloczek ten nosi nazwę JSON Content Reader, a jego wygląd oraz najważniejsze opcje konfiguracyjne widoczne są na zdjęciu obok. W tym przypadku bloczek ten skonfigurowano tak, by pobierał dane z pliku o formacie JSON (opcja "External File"). Użytkownik może wskazać pożądany plik za pomocą eksploratora Windows, albo podać równanie, którego wynik będzie ścieżką dostępu do pożądanego pliku - przydatne przy imporcie wielu różnych plików. |
 Bloczek funkcyjny importu danych JSON w BridgeWorX Bloczek funkcyjny importu danych JSON w BridgeWorX |
Kolejny krok to określenie metody odczytu danych przez system. W tym przypadku użyto opcji "Parse as Name-Value Pairs". Powoduje ona dodanie do zestawu danych wyjściowych tego bloczka osobnego rekordu dla każdej wartości odczytanej z pliku. Dodatkowo z zaznaczoną opcją "Include Array Indices" możliwe jest wyciąganie pojedynczych wartości z wektorów przechowywanych w pliku. Każdy rekord składa się z dwóch kolumn: "PropertyName" oraz "PropertyValue". Pierwsza z nich przechowuje nazwę zmiennej zdefiniowanej w pliku JSON, która jest aktualnie odczytana, natomiast druga - jej wartość.
Dla przykładu, w przypadku pliku JSON o poniższej strukturze (używanego również na potrzeby omawianego tu projektu), opcja "Parse as Name-Value Pairs" spowoduje dodanie 4 nowych rekordów dla każdej wiadomości.
{
"MSG": [
{
"Folder": "SQL_QUERY_ENGINE_DATA",
"Time": "2015/12/01 08:45:00",
"TAG": "Offline_TAG",
"Value": "50"
}
]
}
Jeśli natomiast nieco zmodyfikujemy plik, umieszczając na przykład dwuelementowe wektory z nazwami zmiennych i ich wartościami w każdej wiadomości, to powyższa opcja zwróci już 6 rekordów na każdą wiadomość.
{
"MSG": [
{
"Folder": "SQL_QUERY_ENGINE_DATA",
"Time": "2015/12/01 08:45:00",
"TAG": ["Offline_TAG", "Offline_TAG_2"],
"Value": ["50", "60"]
}
]
}
W tym przypadku zestaw rekordów dla danych wyjściowych z bloczka JSON Content Reader, dla pojedynczej wiadomości, będzie wyglądał jak poniżej.
| Numer rekordu | Property Name | Property Value | ||
| 1 | MSG[0].Folder | SQL_QUERY_ENGINE_DATA | ||
| 2 | MSG[0].Time | 2015/12/01 10:00:00 | ||
| 3 | MSG[0].TAG[0] | Offline_TAG | ||
| 4 | MSG[0].TAG[1] | Offline_TAG_2 | ||
| 5 | MSG[0].Value[0] | 50 | ||
| 6 | MSG[0].Value[1] | 60 |
Kolejne elementy algorytmu
|
Przed budową samego algorytmu warto dodać jeszcze listę zmiennych globalnych w BridgeWorX, jak na zdjęciu niżej. Zawiera ona dwa elementy - zmienną przechowującą liczbę wszystkich wiadomości w pliku oraz numer tej aktualnie przetwarzanej. Przydadzą się one do określenia kiedy algorytm powinien się zakończyć oraz który rekord z wyjścia bloku JSON Content Reader należy przetworzyć w danej chwili. Teraz, do posiadanego algorytmu można dodać bloczek "Real Time Output", który do pierwszej zmiennej z listy zapisze ogólną liczbę wiadomości odczytanych z pliku JSON, natomiast drugą zainicjuje wartością zerową. |
 Lista zmiennych globalnych w BridgeWorX Lista zmiennych globalnych w BridgeWorX |
Kolejny etap to dodanie (początkowo pustej) pętli, która wykona się tyle razy, ile wiadomości zawarto w obecnie przetworzonym pliku JSON. W tym celu należy dodać bloczek "Condition" porównujący dwie zmienne zainicjalizowane wyżej. Jeśli zmienna określająca numer aktualnej wiadomości będzie mniejsza od ich ogólnej liczby, wtedy trzeba ją zwiększyć o 1 (za pomocą bloczka "Real Time Output") i znów sprawdzić warunek. Gdy zmienne się zrównają - algorytm zakończy się.
|
Inicjalizacja zmiennych - liczników. |
Pętla w algorytmie BridgeWorX |


| Ostatni już krok to dołączenie do tej pętli bloczka o nazwie "Data Manipulator". Użytkownik wskazuje dla niego element Data Manipulator utworzony za pomocą narzędzia GridWorX na początku tego wpisu. Bloczek ten umieszcza się tu w celu zarchiwizowania importowanych danych w bazie Hyper Historian. BridgeWorX sam wykryje parametry, jakich dany Data Manipulator potrzebuje, natomiast użytkownik musi przypisać do nich odpowiednie części rekordów pochodzących od bloczka JSON Content Reader. | 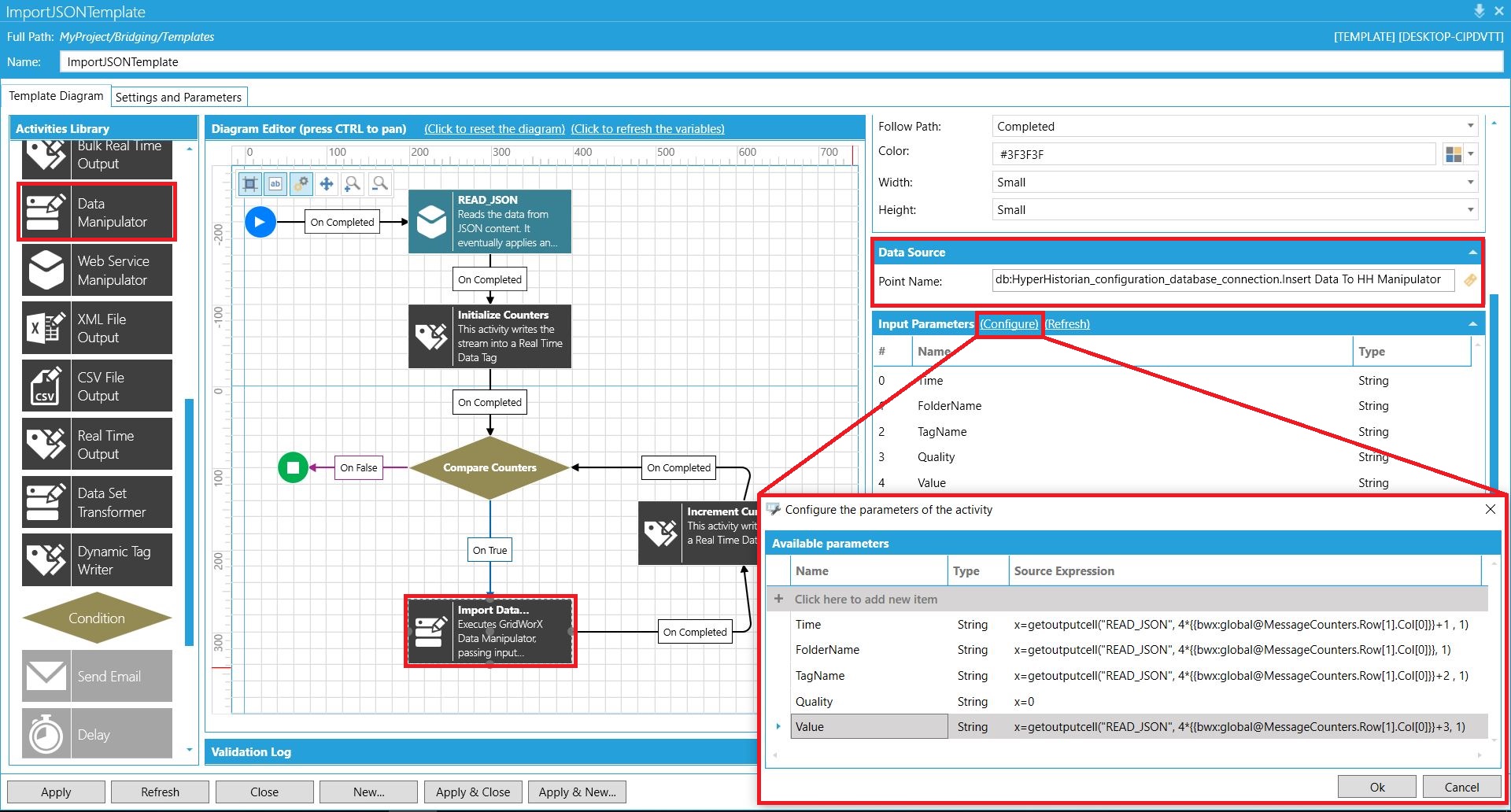 Data Manipulator w pętli algorytmu BridgeWorX Data Manipulator w pętli algorytmu BridgeWorX |
W każdym obiegu pętli nastąpi odczyt odpowiednich informacji z zestawu danych wyjściowych bloczka JSON Content Reader - za pomocą funkcji getoutputcell(...), a następnie przekazanie ich jako parametrów do przygotowanej wcześniej procedury importu do bazy danych SCADA.
Funkcja getoutputcell przyjmuje argumenty:
- unikalną nazwę bloczka,
- numer rekordu (może być to wyrażenie, którego wynikiem jest pożądany numer),
- numer kolumny (w tym przypadku to 1).
Automatyczne wykonywanie algorytmu
|
Teraz, należy przyporządkować gotowy szablon do jakiejkolwiek Transakcji utworzonej pod konfiguracją BridgeWorX. Jeśli nie wiesz jak to zrobić, odpowiedzi znajdziesz w artykule o podstawach BridgeWorX, do którego link podano na początku poprzedniej sekcji. Posiadając aktywną transakcję realizującą odpowiedni szablon algorytmu, należy przejść do zakładki "Transaction Execution". Tam przypisuje się triggery, które mają na celu wyzwalanie tej transakcji. W tym przypadku należy podać trigger skonfigurowany na początku wpisu. |
 Przyporządkowanie triggera do transakcji w BridgeWorX Przyporządkowanie triggera do transakcji w BridgeWorX |
Podsumowanie i prezentacja
Przede wszystkim należy zaznaczyć, że odczyt oraz import danych JSON do systemu SCADA zaprezentowano tutaj w sposób uproszczony. W celu zwiększenia przejrzystości przykładu, a więc minimalizacji jego skomplikowania założono, że w jednej wiadomości znajdują się zawsze informacje odnośnie jednej zmiennej. Co więcej, założono, że każda wiadomość składa się z takich samych elementów.
|
Oczywiście, zaprezentowany tutaj algorytm można rozbudować,a przez to uogólnić. Dodając więcej instrukcji warunkowych oraz pętli, za pomocą jednego algorytmu można obsłużyć dużo większą ilość plików reprezentujących więcej wariantów przekazywania wiadomości. Dodatkowo, tworzenie szablonów projektów jest możliwe w oparciu o parametry, dzięki którym już na etapie wywołania algorytmu staje się on bardziej spersonalizowany. Cała procedura opisana tutaj, jak również jej rezultaty przedstawiono na filmie pokazowym. |
BridgeWorX to rozbudowane narzędzie dające wiele możliwości aplikacjom działającym w każdej gałęzi przemysłu. Aby lepiej zapoznać się z jego funkcjonalnościami, warto samemu spróbować wdrożyć rozwiązania oparte na własnych pomysłach. W tym celu Elmark Automatyka udostępnia bezpłatnie wersję DEMO pakietu GENESIS64 wyposażoną w narzędzie BridgeWorX.


















